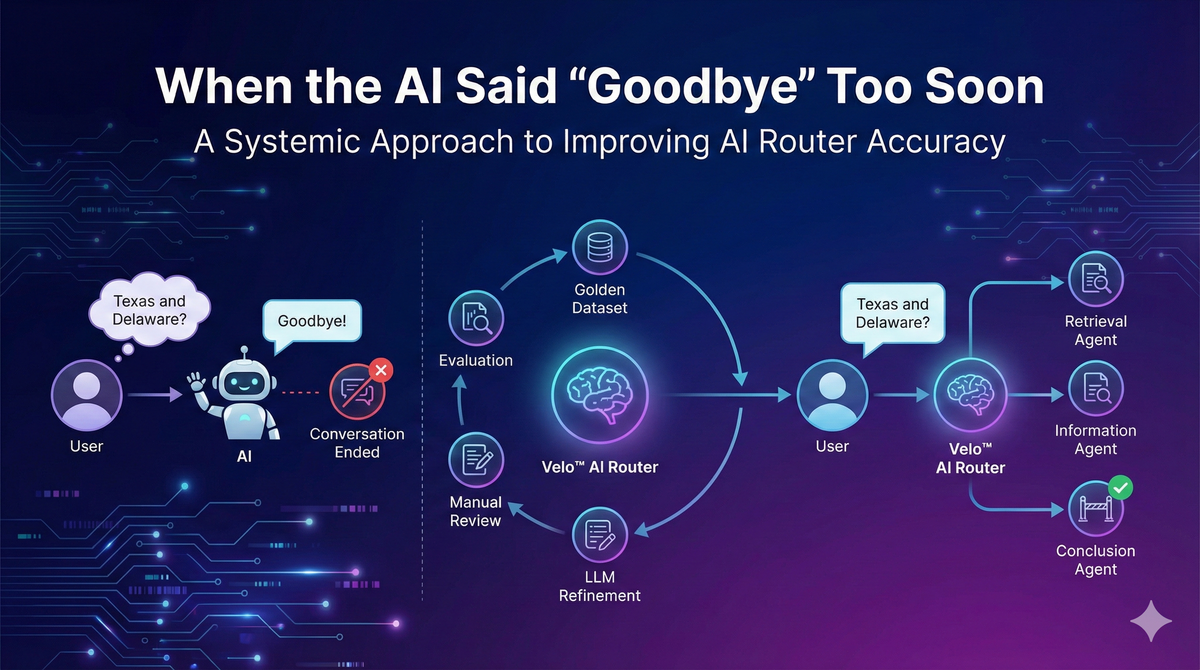
When the AI Said "Goodbye" Too Soon: A Systemic Approach to Improving AI Router Accuracy
What is the router ?
Every message into Velo™ goes through one agent: the router. The router's job is to examine the conversation and select exactly which downstream agent should respond. It could be checking order status, retrieving context from the knowledge base, concluding the conversation, or any other agents.
This routing decision is the most important component of the system. Get it wrong, and users either receive irrelevant responses or feel ignored when they still need help.
How does the router work?
The router selects the right agent in two stages:
- Hard rule: filter by message type (e.g., greet, text, next), user entitlements, and prior agent invocations
- LLM: an LLM tool-call chooses the one agent to invoke based on the thread context and agents definitions (toolspec)
What is the conclusion agent?
It’s the agent that closes a conversation when the user is done with the conversation so we don’t end up in an endless loop.
What is the problem?
After running the router in production for some time, we noticed that the conclusion agent was firing when users weren't done.
A false negative (missing a real goodbye) means several extra messages. A false positive (concluding when the user has questions) makes the user feel ignored and it is not a good user experience.
Example from production
> Velo™: What are the two states you're considering? I can provide more specific information about their naming requirements.
The user answered:
> User: Texas and Delaware
> Velo™: I don’t have any additional pressing suggestions.
Process to improve the router selection
- build a golden dataset from production failures
- create an evaluation script with clear metrics
- iterate on the toolspec by feeding the eval run results back to LLM
- review the fine-tuned prompt manually
- validate changes after deployment to production
Read the conversations (golden dataset )
The hardest part but most important part of testing and debugging any LLM interaction is reading actual user conversations. You need to see exactly what the user said, which agent was selected, and how it responded.
This isn't scalable, and it's tedious. But there's no substitute for it. You could use an LLM as a judge to scale up evaluation, but that approach has its own costs: the judge itself needs fine-tuning and evaluation. There's no free lunch.
I spent hours going through production threads, looking for patterns in the failures. Some were obvious misclassifications. Others were edge cases where the user's intent was ambiguous even to me. I added failures to the golden dataset as I found them.
We also add good examples (cases where conclusion was correctly selected) to the dataset. If we only fine-tune on failures, the prompt would over-correct and never invoke conclusion at all. The dataset needs both.
- Failure cases: "Texas and Delaware" → conclusion (wrong)
- Success cases: "No thanks, I'm all set" → conclusion (correct)
When we find an example worth adding (failure or success), we save it directly to our evaluation platform.
Our internal tool captures:
- The conversation thread (messages)
- The tool call that was selected
- The correct tool call
- Notes
Each example goes into a versioned dataset. We maintain many different golden datasets for different agents and purposes, but this is the one we use for evaluating router text trigger behavior. The platform handles versioning automatically so we can trace which dataset version produced which results.
Evaluation metric and script
For each example in the dataset, did the router select the correct agent?
Accuracy = (Correct selections) / (Total examples)
The router chooses from several agents: retrieval, information, support escalation, conclusion, reject request, and others. The dataset has examples for all of them, not just conclusion. We want to fix conclusion's false positives without breaking selection for the other agents.
How tool call matching works
The core metric is simple: exact-match comparison between the model's output and the ground truth. The dataset contains the correct tool call for each example, and we compare the router's actual selection against it. Results are aggregated as a percentage of correct selections.
We also validate that the router returns exactly one tool call (not zero, not multiple) to ensure consistent routing behavior.
Finally, we check that tool calls include the correct parameters and not just the right tool name, but the right arguments. A call to `search(user_query, category: "A")` when the correct answer was `search(user_query, category: "B")` is still a failure.
The evaluation script:
- Loads the golden dataset
- Runs each example through the router
- Compares the selected agent to the labeled correct agent
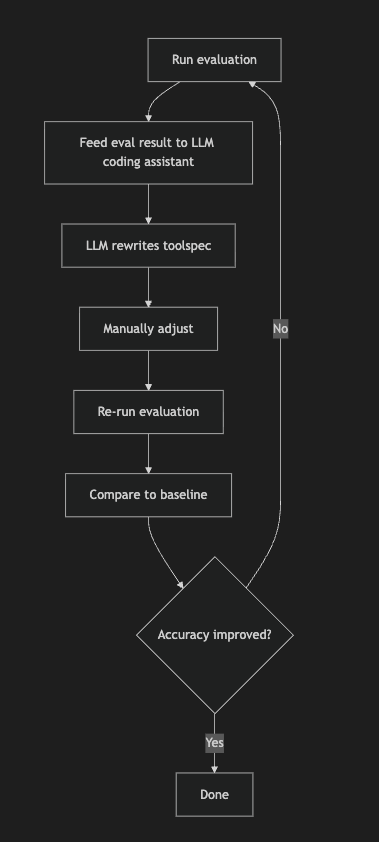
Iterative improvement process
Each cycle starts with running the evaluation. I wrote a script to fetch the results and expose them to an LLM coding assistant. The script pulls each result from the eval platform, extracts the conversation messages, the ground truth tool call, the model's actual output, and whether it matched. I filter to the relevant cases: where the target tool should have been selected but wasn't, and where it was selected but shouldn't have been. The script formats these failures as a table and prints them to the terminal. The LLM coding assistant reads the output and proposes toolspec changes based on the patterns it sees. After manual review and adjustment, I re-run the evaluation and compare against the baseline. If accuracy hasn't improved, I loop back and try again. This human-in-the-loop approach prevents overfitting while leveraging LLM capabilities for rapid iteration.
Manual adjustment is essential
The LLM coding assistant was great at proposing changes, but it tended to overfit. It would add one-shot examples that matched the specific failures rather than general rules.
I had to manually adjust after each iteration:
- Replace specific examples with general patterns
- Remove rules that were too narrow
- Check that fixes didn't break other agents
Initial toolspec for conclusion agent (before iterations):
Use this tool ONLY when the user CLEARLY signals they want to end
the conversation or are satisfied with the assistance provided.
Examples include:
- "No thank you"
- "That's all"
- "I'm good"
- "Thanks, that's everything"
- "I don't need anything else"
- "Goodbye"
- "Have a good day"
This tool should be used when the user indicates they are done with
their current request or conversation.
It should NOT be used if the user indicates they would like to proceed
with an action suggested by the assistant.
The overfitting problem
Once the LLM coding assistant had access to the eval results, it started pattern matching on failures. When it saw cases where conclusion was wrongly selected, it would propose rules to fix those specific mistakes. But the suggestions often crossed boundaries between agents.
Example of few-shot added via LLM coding assistant to router's toolspec:
If message contains "?" → use retrieval() instead
Why this is problematic
The router has several agents, each with their own toolspec: knowledge base search, account lookup, support escalation, and conclusion (end conversation).
- "How do I reset my password?" → knowledge base (educational content)
- "What is MY account status?" → account lookup (user-specific data)
- "Can I talk to someone?" → support escalation (human request)
The conclusion toolspec should only decide "conclude or don't conclude." It shouldn't prescribe which other agent handles the message. That's what the other toolspecs are for.
The fix
In my manual revisions, I kept the question mark rule but removed the routing logic:
# Bad (from LLM coding assistant):If message contains "?" → use search() instead
# Good (my revision):If the user's message contains a question mark (?), DO NOT use conclusion.
No mention of search, account lookup, or any other agent. Just "don't conclude here." This lets the other agents' toolspecs compete for the message based on their own criteria.
The results
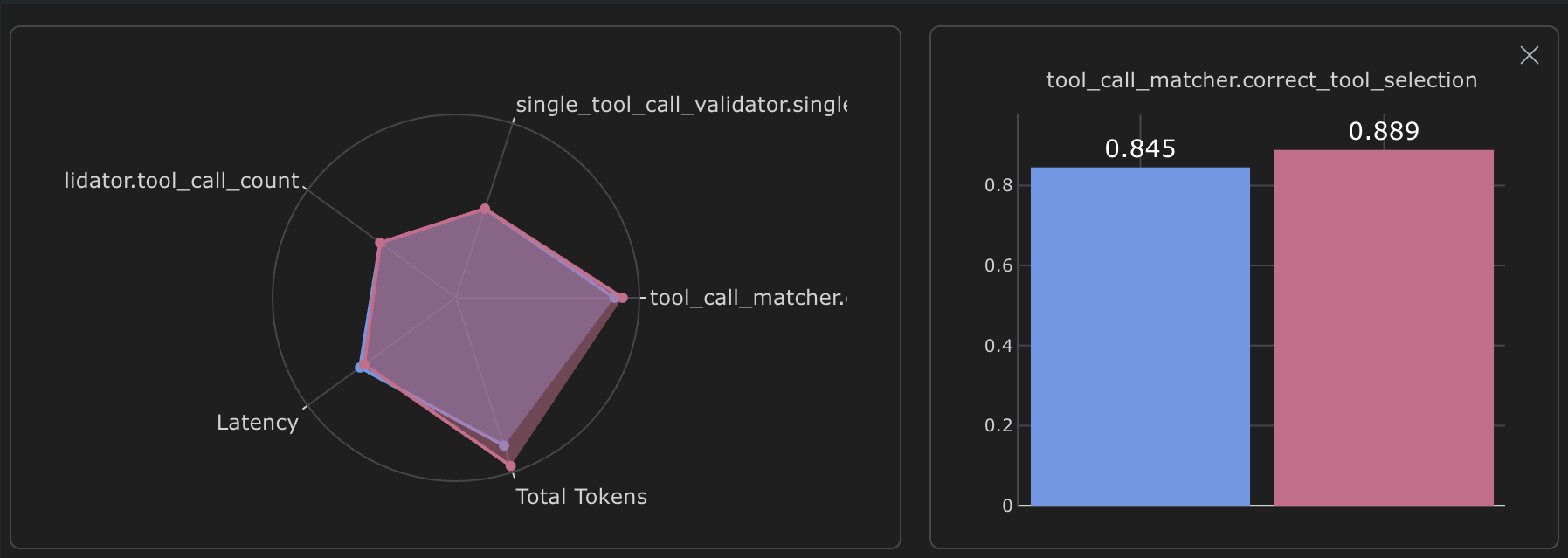
After 12 rounds of iteration, I found a toolspec that improved conclusion accuracy without degrading the router's performance on other agents.
Router accuracy jumped from 84.5% to 88.9%, a 5 percentage point improvement.
This might sound modest, but the router is the most important component of the system. Every single message goes through it. A 5-point accuracy boost translates to thousands more accurate interactions.
Post-deployment validation
Evaluations on your golden dataset are helpful, but they can't capture everything. Real production traffic has edge cases, conversation patterns, and user behaviors that you won't see in even the most carefully curated dataset. That's why post-deployment validation is critical.
After deploying the improved toolspec, I manually reviewed 300+ threads where conclusion was invoked in production. Unlike traditional software APIs, LLM outputs can vary, so we cannot rely only on our test cases from the golden dataset. The only way to know if it's working is to check production conversations.
What I found:
Despite a slight uptick in conclusion invocations (the new toolspec was more confident about real conclusions), I only found less than 1% failures for conclusion agent triggers.