Mitigating LLM Outages: The Big Red Button


When a SaaS provider has an incident, most of the time any software that's downstream of the issue will also experience some form of outage. In a perfect world, these integrations are built with a reasonable fallback - beyond a friendly, "Oh no, our stuff is broken!" error message. Unsurprisingly, integrating with LLM providers is no different from any other service that might sometimes fail or become unresponsive!
The AI platform team maintains a service that acts as a gateway for all LLM interactions at ZenBusiness. Our model gateway is first in the line of fire when a model provider is down. As such, the team is in a unique position to own the recovery mechanisms for when an outage occurs.
Setting the Stage
Let's say OpenAI is experiencing an incident that results in a full outage, meaning getting completion responses from their API is impossible. In this case, if our model gateway gets a request for a completion using GPT-5, we'd have no way to fulfill it. Maybe we could return the error from the provider, or even catch the provider error and respond with a 503 to our callers... but what if we could instead route the request to an entirely different LLM provider? Sure, it wouldn't be a completion from GPT-5, but getting something is better than nothing. Introducing the Big Red Button: the AI platform team's first LLM provider outage recovery mechanism.
How It Works
The Big Red Button is our fun name for what is actually an incredibly simple mechanism. It's nothing more than a global model override setting for the completions endpoint offered by our model gateway. If an active model override exists in our database, then any request made to our completions endpoint will use the model that's defined by the override record instead of the model specified by the incoming request. So, calling back to our previous imaginary scenario - if OpenAI is down and we get a request for a completion using GPT-5, then all we need to do in order to prevent such requests from failing is "smash the big red button" to create a model override record that points at a model that isn't offered by OpenAI. Our model gateway is currently integrated with OpenAI and Gemini; as long as these providers aren't both down at the same time, we should always have a means to generate LLM completions.
The Big Red Button In Action
There was a Gemini incident on 9/29/25. This outage was The Big Red Button's big production debut. At around 11:55 AM CST, our model gateway (and its consumers) experienced a spike of 500 errors.
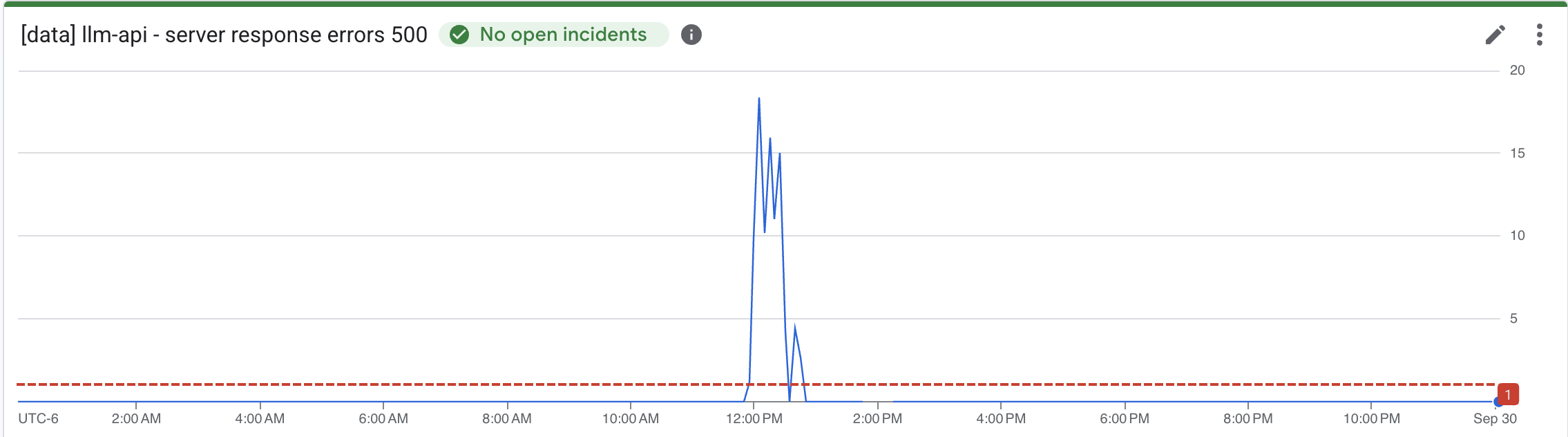
After we determined it wasn’t something we had done (we had just deployed and initially suspected our own change), one of our engineers checked the Gemini status page and found that their API was undergoing a full outage. At this point, we decided to "smash the big red button". We defined a model override targeting gpt-4o and quickly saw our flood of 500 errors disappear. 🎉
This meant every completion request flowing through our model gateway was being forced to use gpt-4o. This doesn't come without side effects, but at least we were able to successfully fulfill every completion request during Gemini's outage.
Performance Side Effects
Model latency for OpenAI is generally a lot higher than models offered by Gemini. Forcing all requests to use gpt-4o increased our average request latency. While not ideal, it was a worthwhile tradeoff considering the other option was failing every Gemini-bound request.
Prompts written and evaluated for Gemini models will likely behave differently when paired with a different model, like gpt-4o. At some point in the future, in addition to evaluating prompt performance with a 'primary target' model (the model we intend the prompt to be paired with in production), we'll also evaluate prompt performance with a secondary model from a different provider in order to better understand how latency and outputs change when we need to use the Big Red Button again.
Future Improvements
Today, the big red button grants us the ability to reroute all completion requests to a different model of our choosing, but rerouting every request through a single model may eventually introduce too many unintended side effects. An improved iteration of the Big Red Button might be to allow for re-mapping specific 'primary' models to other 'backup' models. For example, calling back to the Gemini outage - rather than setting a global model override to gpt-4o, instead we could re-map specific requests for gemini-2.5-flash-lite to gpt-4o-mini. We'll aim to pair models that have similar latency, performance, and cost profiles.
The Big Red Button is a testament to the fact that sometimes the simplest tools make the biggest difference. Next time a model provider takes a nap, we won’t be panicking. We’ll just press the button and keep going.