Awesome Kubernetes Right-Sizing w/ Cast.ai



... Of what Google Cloud Platform (GCP) billed us for GKE (Google Kubernetes Engine) usage lately:
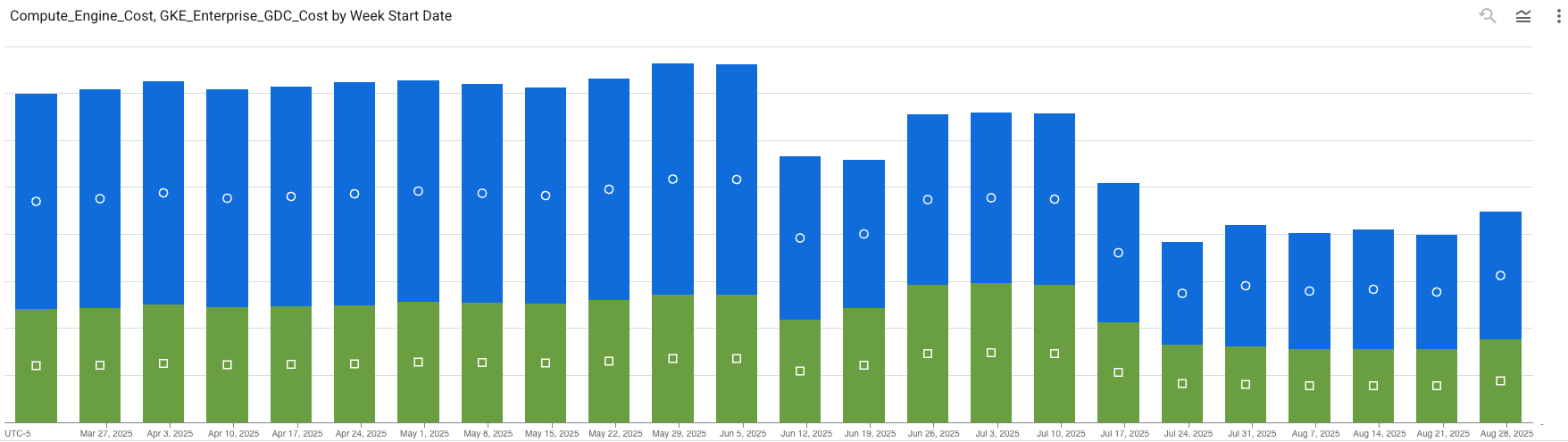
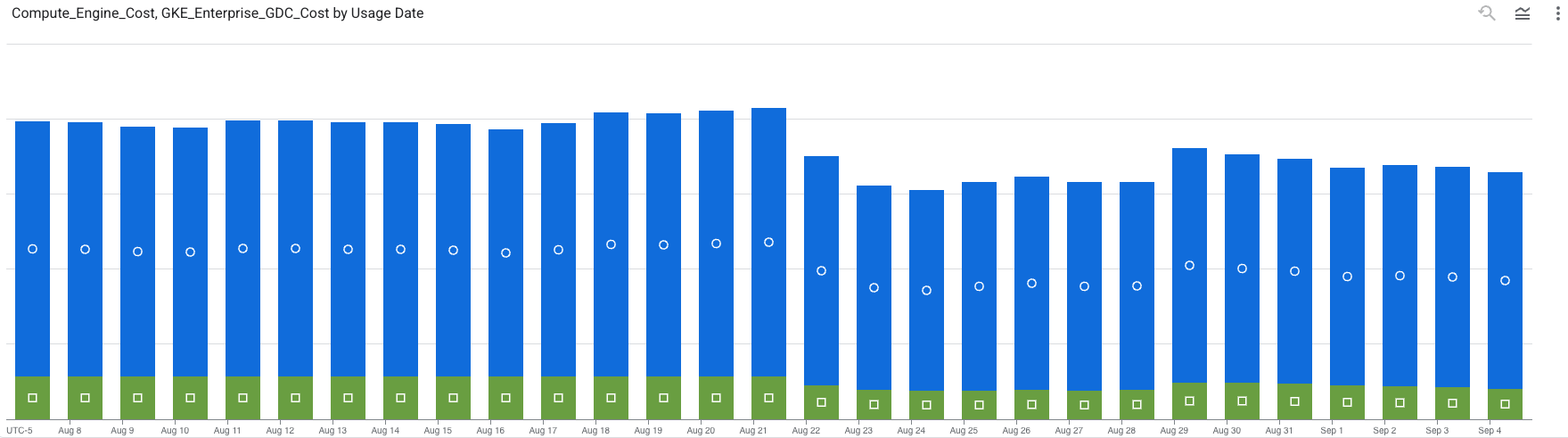
Clearly, something happened at a specific point in time in both of our environments that noticeably reduced our costs. What was that?
It was Cast.ai!
Kubernetes Autoscaling
Kubernetes has mechanisms that let it grow as resource demands grow, so you don’t have to micromanage computer CPU and RAM specifications!
Node Pools - the set of machines that Kubernetes can run workloads on. Kubernetes can adjust the nodes in a pool depending on the demands made by workloads that get assigned to the pool.
Workloads - the CPU and Memory constraints of particular task. Kubernetes can adjust the limits of workloads as they get more demanding.
Guessing At Your App’s Resource Needs
Maybe you’ve had to go and “give your app more memory” or increase your app’s CPU limit before.
Hang on, wait, why did you have to do that? Wasn’t autoscaling supposed to automatically scale your app’s resources to where they were big enough?
Well, yeah, turns out that’s hard sometimes. Kubernetes & GCP have a lot of clever code to handle and enable that but the real world w/ real apps can manage to be more-complex!
And on top of that… autoscaling would definitely eventually probably get things big enough. But you know, 100GB is big enough for an app that only needs 1GB. You want automatic scaling up and down - you want right-sizing for a truly “set it and forget it” experience!
Cast.ai Guesses Better and Faster
That’s what Cast offers: a vendor whose job it is to write even-more-clever Kubernetes right-sizing code that you can turn loose and just stop worrying about configuring resource limits. You will efficiently grow and contract with demand.
Node Pools
Cast manages node pool autoscaling, and also a thing they call “rebalancing” which is similar in concept to “defragmenting.”
Imagine: Your cluster gets busy during the day, so more nodes are needed to host more instances of your applications. Later, traffic dies down and some instances are shut down. You still have 3 extra nodes, each running at 1/3 capacity, though. You could combine the instances on those 3 nodes into one single node - they’d fit!
The Rebalancer does this. You can schedule it to run automatically on a cadence (and this is what Cast recommends) to maximize the resources you can reclaim after a node pool scales up. Our Dev cluster rebalances each morning before the workday begins.
Workloads
How much memory does your app need? Well, you can’t see the future but you can see the past! Cast can take up to 7 days of usage history into account when forecasting the likely-correct CPU & RAM needs of an app. A certain % of overhead is configurable as well, and recommendations are reassessed at 15-minute intervals.
The end-result is that apps grow their resources to where they need to be faster than a human could do it manually, and they release unneeded resources faster too.
HPA, VPA, oh my!
There’re two major kinds of autoscaling in k8s:
- Horizontal Pod Autoscaling (HPA): Makes more pods (more copies of an app) as CPU and/or RAM usage approaches the limits
- Vertical Pod Autoscaling (VPA): Increases the CPU and/or RAM requests for a single instance of an app, as it usage approaches the limits.
Traditionally, if you wanted to do both of these in GKE you had to pick one metric (CPU or RAM but not both) for HPA, and the other for VPA.
Cast can do both of these at the same time, for both CPU and RAM!
We’ve left HPA in the hands of Kubernetes' default autoscaler, and run it only for CPU. VPA for memory and CPU is handled by Cast.
What this configuration means in practice is that “vanilla Kubernetes” will give an app more pods as the app is asked to do more work, and Cast will be intelligently adjusting the CPU and RAM per pod based on “how hard” that pod’s work is. These will be happening together, intelligently, to give an app the best chance of success!
Neat Features
Heterogenous Node Pools
✅ We’re doing this!
Normally, when you define a node pool in Kubernetes, you probably fill it with nodes of the same type, because that’s just easier and how on earth would you be able to figure out a better mix of the 100s of node types available in most cloud providers?
Cast can! When Cast creates new nodes in node pools, it picks the best-fit in terms of (configurable) cost and resource constraints. This means you might end up with a K8s node pool full of different types of nodes. Here’s a recent snapshot of the mix of Google Compute Engine (GCE) node types it picked for the production cluster in a recent rebalance:
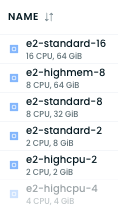
And this is totally OK, because the composition will keep changing as the cluster scales up and down, staying at the most cost-effective way to meet the needs of the cluster!
Custom Scaling Profiles
✅ We’re doing this!
Not all workloads are created equal. Some are “bursty” and have occasional huge spikes in resource demands. These need to be able to grow more-rapidly than other workloads (but can also probably shrink more-rapidly, too)! Other workloads are much less fault-tolerant, and would benefit from a permanent, large resource overhead so that they don’t have to be rescheduled or restarted during spikes.
Cast allows for this. For example, all our Jobs - Cron & otherwise - are “burstable” now - meaning they’ll scale up faster than apps when they approach CPU or RAM limits.
Safe Spot Instances
⏳ We’re not doing this yet!
A “spot instance” in a cloud provider is a cheaper machine that could be yanked away from you at any moment in order to meet the needs of someone else who’s paying full price. For fault-tolerant workloads in fault-tolerant systems (like Kubernetes), this is often a downside-free way to save money on compute costs.
Our dev cluster’s workloads run entirely on spot instances.
Our production cluster’s workloads run entirely on “on-demand” (non-spot) instances.
There are colossal savings to be had if we could introduce spot instances to production. Cast offers many mechanisms to do this slowly & safely just in case our prod workloads aren’t as fault-tolerant as we’d like!
They’ll handle things like
- spot instance quota - want 10% of workloads to be on spot? 20%? Cast can do that across the cluster while also making sure that no more than 10% of any workload is on spot. So it’s not that 1 in 10 apps will end up entirely on spot instances & be less-reliable, but 1/10th of each app. And then you can dial that up…
- spot instance type distribution - filling your spot instances with different types reduces the chances of them all being yanked away at once, artificially increasing the reliability of spot instances.
- spot instance preemption watch - across all their customers in all their clouds, Cast can see spot preemptions happening and preemptively, gracefully move workloads off of spot instance types that are experiencing high rates of preemption right now
- on-demand fallback - after a certain threshold of disruption, Cast can prevent a workload(s) from being scheduled on spot instances and provision non-spot nodes, guaranteeing a minimum availability during “bad times” for spot instances.
How Much Does This Cost?
Cast's sales pitch included that customers usually saved somewhere in the 25-60% range on Kubernetes costs, and that Cast usually billed customers less than the savings worked out to. This means that - at least for the first year - most people end up functionally being paid to use Cast! Or so they claimed...
For us... well, our first year isn't over yet, but the results so far, projected out... yeah, we're keeping a two-digit percentage of Kubernetes cost savings in our pockets after paying Cast.
Awesome!